

研究室に配属されたばかりの新入生や、これからRで統計分析を始めたいと思っている方へ向けて、【R講座】では、RとRStudioの基本的な使い方から統計手法の選び方、基本的なデータ分析方法を解説しています。特にRが初めての方でも安心して学べるように、RStudioのクリック操作も紹介していきます。実際のコード例を交えながら進めるので、これからの研究やデータ分析に、役立てていただけたら嬉しいです。
みなさん、こんにちは!
前回のR講座では、プログラミングの基本とオリジナル関数の定義について解説しました。

今回は、データフレームの基本とデータ入力について紹介していきます。
- データの形式
- データフレームの特徴
- データの入力の注意点
- データの読み込み
データの形式
データを扱う際には、どの形式で保存・管理するかが重要です。データの形式は、表計算ソフト(Excel など)や分析機器からの出力、統計ソフトでの処理など、用途によって適切なものを選ぶ必要があります。
ここでは、データフレーム・CSV・TXT・TSV など、よく使われるデータ形式について説明します。
データフレーム(DataFrame)
ID Name Age
1 1 Tanaka 25
2 2 Yamada 30
3 3 Suzuki 28- R や Python などのデータ分析ツールで扱う表形式のデータ構造
- 列ごとに異なるデータ型(数値・文字列・因子など)を持つことができる
data.frame()やtibble()を使って作成
- データ解析ソフト(R, Python)で直接操作可能
- dplyr などを使うことで集計・可視化が簡単
- R や Python 以外ではそのまま利用できない
- 保存する際は CSV や Excel に変換が必要
TXT(プレーンテキストデータ)
ID Name Age
1 Tanaka 25
2 Yamada 30
3 Suzuki 28- テキスト形式で保存されたデータ
- 区切り文字(タブ, カンマ, スペース)を使ってデータを分ける
- 拡張子は .txt
read.table()で読み込み可能
- シンプルな形式でどんな環境でも開ける
- 列の区切りが曖昧になりやすい(スペースの数が不揃いだとエラー)
CSV(Comma-Separated Values, カンマ区切り)
ID,Name,Age
1,Tanaka,25
2,Yamada,30
3,Suzuki,28- カンマ(,)で区切られた表形式のテキストファイル
- Excel, R, Python, 分析ソフト など、多くのツールで利用可能
- 拡張子は .csv
read.csv()やwrite.csv()で読み書き
- 表計算ソフトで開ける
- どの環境でも読み書きしやすい
read.csv()で簡単に読み込める
- カンマがデータに含まれると誤認識される可能性
("Tanaka, Taro" など)
TSV(Tab-Separated Values, タブ区切り)
ID Name Age
1 Tanaka 25
2 Yamada 30
3 Suzuki 28- タブ(\t)で区切られたデータ
- CSV に似ているが、カンマの代わりに タブ(TABキー) を使用
- 拡張子は .tsv
read.delim()で読み込み可能
- データ内にカンマ(,)が含まれていても問題なし
- メモ帳やテキストエディタで開くと見にくい
Excel(.xlsx, .xls)
- Microsoft Excel の標準フォーマット
- 拡張子は .xlsx(新しい形式) または、 .xls(古い形式)
readxl::read_excel()やopenxlsx::read.xlsx()で読み込み可能
- データ入力が直感的で、表計算・フィルタ機能も使える
- 多くのビジネス環境で使われる
- R で直接読み込むにはパッケージ(readxl など)が必要
- 数式(=SUM(A1:A5) など)が含まれると注意
このほかにも、次のようなデータ形式があります。
| 形式 | 説明 |
|---|---|
| JSON(.json) | Web API やデータ交換で使われる階層構造データ |
| XML(.xml) | マークアップ言語で、データの構造を記述 |
| SQLite / MySQL | データベース形式(大量のデータ管理に向く) |
用途に応じて最適なデータ形式を選ぶことで、スムーズなデータ分析が可能になります。
データフレーム
Rのデータフレーム (data.frame クラス) は、統計解析において最もよく使われるデータ構造の一つです。ここでは、データフレームの基本概念から作成・操作・結合方法まで、具体例を交えながら詳しく解説します。
データフレームの特徴
データフレームは異なるデータ型(数値・文字列・因子など)を持つ列を含むリスト構造ですが、行列のような外見を持ちます。
データフレームの例として、Rに標準で搭載されている「iris」のデータを表示します。
# 「iris」を最初の方だけ表示
head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa- 列(変数)は必ず同じ長さを持つ
- 行・列のラベル(名前)を持ち、それを使った操作が可能
- ベクトルやリストから作成でき、統計解析が容易になる
summary()関数を使って各列の基本統計量を確認できる
データフレームの作成
データフレームは data.frame()を使って作成できます。
# 身長、体重、性別のデータを作成
df <- data.frame(
身長 = c(170, 165, 180, 175),
体重 = c(65, 55, 75, 70),
性別 = c("男性", "女性", "男性", "男性")
)
# データフレームの表示
print(df) 身長 体重 性別
1 170 65 男性
2 165 55 女性
3 180 75 男性
4 175 70 男性データの列の特徴を確認
summary()を使うと、データフレームの各列ごとに統計量が表示されます。
# 身長、体重、性別のデータを作成
df <- data.frame(
身長 = c(170, 165, 180, 175),
体重 = c(65, 55, 75, 70),
性別 = c("男性", "女性", "男性", "男性")
)
# データの要約
summary(df) 身長 体重 性別
Min. :165.0 Min. :55.00 Length:4
1st Qu.:168.8 1st Qu.:62.50 Class :character
Median :172.5 Median :67.50 Mode :character
Mean :172.5 Mean :66.25
3rd Qu.:176.2 3rd Qu.:71.25
Max. :180.0 Max. :75.00 データフレームからデータを取り出す
データフレーム内の特定のデータを取り出す方法について説明します。
# データを抽出
df["身長"] 身長
1 170
2 165
3 180
4 175# データを抽出
df[["身長"]] [1] 170 165 180 175df[, "身長"] または、 df$身長 も同じ結果が得られます。
[1] 170 165 180 175データフレーム名に続いて角括弧[]内に行, 列の順で取り出したいデータを指定します。
# インデックスを使った抽出
df[1, ] # 1行目のデータ
df[, 2] # 2列目(体重)
df[1:2, ] # 1〜2行目のデータ[1] 170 165 180 175attach() と detach() の使用
attach()を使うと、データフレームの列を $ を使わずに直接アクセスできます。
attach(df)
print(身長) # df$身長 ではなく、「身長」だけでアクセス可能
detach(df)[1] 170 165 180 175attach()したデータフレームで作業が終了したら、detach()しましょう。detach() しないと、他のデータフレームを attach() したときに混乱の原因になります。
データの列の変更・追加・削除
データフレームの列を次の方法で編集できます。
変更したいデータフレームの列を指定し、代入して既存のデータに上書きします。
# 体重のデータを変更
df$体重 <- c(68, 57, 78, 72)
# 体重の列を表示
df$体重[1] 68 57 78 72データフレーム名$〇〇 と新しいデータフレーム要素を追加し、そこにデータを追加します。
# 新しいデータの追加
df$BMI <- df$体重 / (df$身長 / 100)^2
# データの表示
df 身長 体重 性別 BMI
1 170 68 男性 23.52941
2 165 57 女性 20.93664
3 180 78 男性 24.07407
4 175 72 男性 23.51020削除したいデータフレームの列を指定し、NULLを代入して列を削除。
# "BMI" 列を削除
df$BMI <- NULL
# データの表示
df 身長 体重 性別
1 170 68 男性
2 165 57 女性
3 180 78 男性
4 175 72 男性2つのデータフレームを連結
cbind()で列を結合(変数を増やす)dfとdf2を列で結合して、df_combinedを作成します。
# df2を作成
df2 <- data.frame(年齢 = c(25, 30, 28, 35))
# 列方向に結合
df_combined <- cbind(df, df2)
# データを表示
df_combined 身長 体重 性別 年齢
1 170 68 男性 25
2 165 57 女性 30
3 180 78 男性 28
4 175 72 男性 35rbind()で行を結合(データ数を増やす)dfとnew_dataを行で結合して、df_extendedを作成します。
# df2を作成
new_data <- data.frame(身長 = 160, 体重 = 50, 性別 = "女性")
# 列方向に結合
df_extended <- rbind(df, new_data)
# データを表示
df_extended 身長 体重 性別
1 170 68 男性
2 165 57 女性
3 180 78 男性
4 175 72 男性
5 160 50 女性rbind() を使う場合、列名が一致している必要があります。
データフレームは 統計解析や機械学習において必須のデータ構造 です。基本操作をしっかり理解しておくと、Rのデータ処理がスムーズに行えます!
データ入力の注意点
データ分析をスムーズに行うためには、適切な形式でデータを入力・整理することが重要です。不適切なデータ入力は、読み込み時のエラーや解析の困難さを引き起こします。ここでは、適切なデータ入力の原則を説明します。
データは「縦長」形式(tidy data)にする
Rはベクトル計算に特化した言語です。縦長データでは、同じ種類の値が1つの列にまとまるため、ベクトルとして効率的に処理できます。
| 年度 | 地区 | 値 |
|---|---|---|
| 2022 | A地区 | 50 |
| 2022 | B地区 | 40 |
| 2022 | C地区 | 30 |
| 2023 | A地区 | 55 |
| 2023 | B地区 | 42 |
| 2023 | C地区 | 33 |
- ggplot2 などの可視化ツールと相性が良い
- dplyr を使ったデータ処理が容易
- フィルタリングや集計がしやすい
クロス集計表(ワイド形式)は解析に不向きです。
| 年度 | A地区 | B地区 | C地区 |
|---|---|---|---|
| 2022 | 50 | 40 | 30 |
| 2023 | 55 | 42 | 33 |
- 列名に実際のデータが含まれている(A地区, B地区, C地区)
- 分析する際にデータを「縦長」形式に変換する必要がある
余計な空白セルを作らない
Rはベクトル計算に特化した言語です。縦長データでは、同じ種類の値が1つの列にまとまるため、ベクトルとして効率的に処理できます。
| ID | 名前 | 地区 | 年齢 |
|---|---|---|---|
| 1 | 田中 | 東京 | 25 |
| 2 | 佐藤 | 東京 | 30 |
| 3 | 山田 | 大阪 | 28 |
- 必ずすべてのセルを埋める(空白ではなく "不明" などの値を入れる)
- NA が適切な場合は明示的に "NA" を入力する
空白のセルが含まれると、空白のセルに対する前処理をする必要が出てきます。
| ID | 名前 | 地区 | 年齢 |
|---|---|---|---|
| 1 | 田中 | 東京 | 25 |
| 2 | 東京 | 30 | |
| 3 | 山田 | 大阪 | 28 |
- 2行目の「名前」セルが空白 → NA として扱われる可能性がある
- 分析時に意図しない欠損値の処理が必要になる
左上詰で入力する
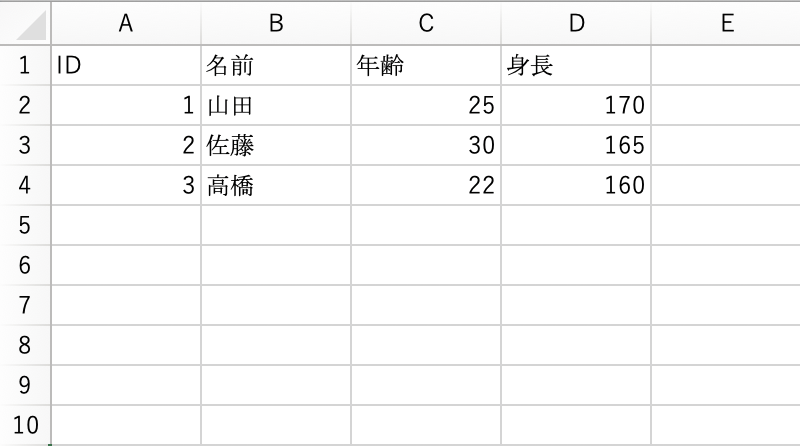
表計算ソフトでデータを入力する際は、左上詰で入力します。
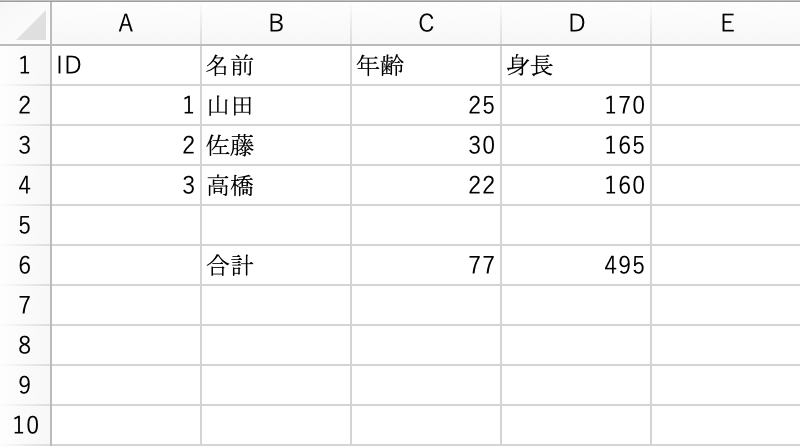
小計の項目が入力されている例
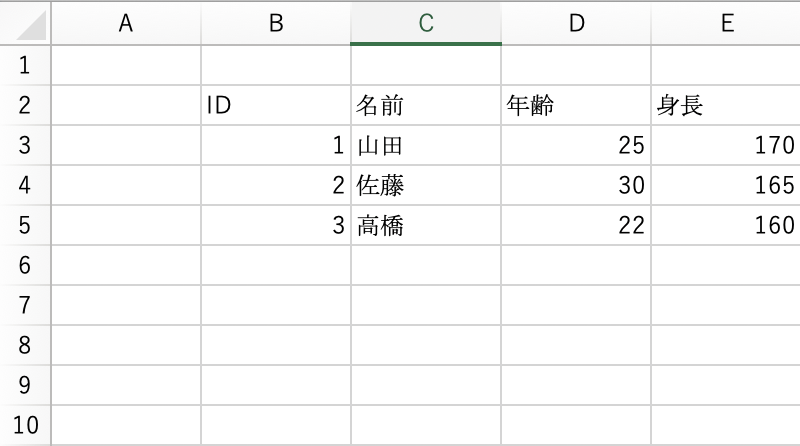
1行1列の空白セルが入力されている例
データは1行1レコードにする
| ID | 名前 | 年 | 売上 |
|---|---|---|---|
| 1 | 田中 | 2022 | 500 |
| 1 | 田中 | 2023 | 550 |
| 2 | 山田 | 2022 | 400 |
| 2 | 山田 | 2023 | 420 |
- 分析や可視化の際に ggplot2 や dplyr をそのまま使える
- 時系列データの処理が簡単になる
| ID | 名前 | 2022年の売上 | 2023年の売上 |
|---|---|---|---|
| 1 | 田中 | 500 | 550 |
| 2 | 山田 | 400 | 420 |
- 売上が年ごとに異なる列に分かれている(縦のデータ構造が適切でない)
- データが「ワイド形式」になっており、処理しづらい
数値・日付・文字列を正しく入力する
| ID | 売上 | 日付 |
|---|---|---|
| 1 | 1000 | 2023-01-01 |
| 2 | 2000 | 2023-01-02 |
- 数値には単位を含めない(1000 ではなく "1000円" と書くと numeric ではなく character になる)
- 日付は "YYYY-MM-DD" 形式に統一(
as.Date()関数で変換しやすい)
| ID | 売上 | 日付 |
|---|---|---|
| 1 | 1000円 | 2023年1月1日 |
| 2 | 2000 | 01/02/2023 |
- 売上のデータ型が不統一 ("1000円" は文字列として認識される)
- • 日付の形式がバラバラ("2023年1月1日" と "01/02/2023")
正しいデータ入力を心がけることで、データ解析がスムーズに進みます。
入力したデータは、tsvファイルやcsvファイルに書き出ししましょう。
| 原則 | 説明 |
|---|---|
| クロス表を作らない | データは「長い」形式(tidy data)にする |
| 空白セルを作らない | すべてのセルを埋める or NA を明示的に入力 |
| 1行1レコード | 年ごとのデータやカテゴリデータを分割しない |
| 数値・日付の形式を統一 | 1000円 ではなく 1000、日付は YYYY-MM-DD |
| 列名は半角英数字で明確に | sales_amount, record_date などわかりやすい名前に |
| データエントリルールを統一 | カテゴリ名や NA の表記を統一 |
データの読み込み
Rでは、さまざまなデータファイルを読み込むことができます。ここでは、CSVファイルやExcelファイル、オンラインデータ、GUIを使用したデータのインポート方法など、実際のコード例を交えて詳しく解説します。
データ読み込み関数の基本
Rではデータの読み込みに多くの関数が用意されていますが、基本的な構造は同じです。
関数名(file = "ファイルパス")
# ファイルパスにはファイルの拡張子を忘れないようにしましょう。
#(例:file = "path/data.csv")
read.table()は、テキストデータをデータフレームとして読み込むための基本的な関数で汎用性があります。テキストファイル(.txt)だけでなく、引数オプションのsep = "\t"でタブ区切りデータ(.tsv)を、sep = "," でカンマ区切りデータ(.csv)を読み込めます。
read.table(file = "ファイルパス", ...)
| 引数 | デフォルト値 | 説明 |
|---|---|---|
| file | なし | 読み込むファイルのパスやURL、または clipboard でクリップボードから取得 |
| header | FALSE | TRUE にすると1行目を列名として扱う |
| sep | "" | 列の区切り文字(CSVなら ","、TSVなら "\t") |
| quote | "\"'" | 文字列を囲む引用符(デフォルトは " " または ' ') |
| dec | "." | 小数点の表記 ("." または ",") |
| numerals | "allow.loss" | 数値変換時の挙動 ("warn.loss": 警告, "no.loss": エラー) |
| row.names | NULL | 行名を指定する列の番号またはベクトル |
| col.names | NULL | 列名を手動で指定 |
| as.is | !stringsAsFactors | TRUE にすると文字列を factor にせず character として保持 |
| tryLogical | TRUE | TRUE にすると "TRUE", "FALSE" を logical に変換 |
| na.strings | "NA" | 欠損値として認識する文字列(例: c("NA", "", "-999")) |
| colClasses | NA | 各列のデータ型を指定(例: c("numeric", "character", "factor")) |
| nrows | -1 | 読み込む行数(-1 は全行を読み込む) |
| skip | 0 | 読み飛ばす行数 |
| check.names | TRUE | TRUE にすると無効な列名を修正 |
| fill | !blank.lines.skip | TRUE にすると列数の異なる行があっても読み込める |
| strip.white | FALSE | TRUE にすると文字列の前後の空白を削除 |
| blank.lines.skip | TRUE | FALSE にすると空白行をスキップしない |
| comment.char | "#" | "#" 以降のテキストを無視 |
| allowEscapes | FALSE | TRUE にすると "\n", "\t" などのエスケープを処理 |
| flush | FALSE | TRUE にすると余分なフィールドを削除 |
| stringsAsFactors | FALSE | TRUE にすると文字列を factor に変換 |
| fileEncoding | "" | 読み込むファイルのエンコーディング(例: "UTF-8", "SJIS", "latin1") |
| encoding | "unknown" | fileEncoding で指定したエンコーディングを考慮するか |
| text | NULL | 文字列を直接データとして読み込む |
| skipNul | FALSE | TRUE にすると NULL 文字 (\0) を無視 |
タブ区切り(TSV)ファイルの読み込み
タブ区切りのTSVファイルを読み込む場合は、read.delim()関数を使用します。read.delim()関数はread.table()関数の派生型で、TSV読み込みに適した設定になっています。
# タブ区切りのデータを読み込む
df <- read.delim(file = "path/data.csv")CSVファイルの読み込み
カンマ区切りのCSVファイルを読み込む場合は、read.csv()関数を使用します。read.csv()関数はread.table()関数の派生型で、CSV読み込みに適した設定になっています。
# CSVファイルをデータフレームとして読み込む
df <- read.csv(file = "path/data.csv")Excel(.xlsx)ファイルの読み込み
Rでは、パッケージをインストールすることでエクセルファイルを読み込めます。
# readxlパッケージをインストール(初回のみ)
install.packages("readxl")
# パッケージを起動
library(readxl)
# Excelファイルの1番目のシートを読み込む
df <- read_excel(file = "path/data.csv", sheet = 1)# openxlsxパッケージをインストール(初回のみ)
install.packages("openxlsx")
# パッケージを起動
library(openxlsx)
# Excelファイルを読み込む
df <- read.xlsx(file = "path/data.csv", sheet = 1)オンラインデータの読み込み
インターネット上のデータファイルを直接Rに読み込むことも可能です。
# Web上のCSVファイルを直接読み込む
df <- read.csv("https://example.com/data.csv")GUIを使ったデータの読み込み
RStudioではGUIを使ってファイルを選択し、データを読み込めます。
file.choose()関数を使うfile.choose()関数はGUIを使ってファイルのパスを取得できる関数です。
# GUIのファイル選択ダイアログを開いてデータを読み込む
df <- read.table(file.choose())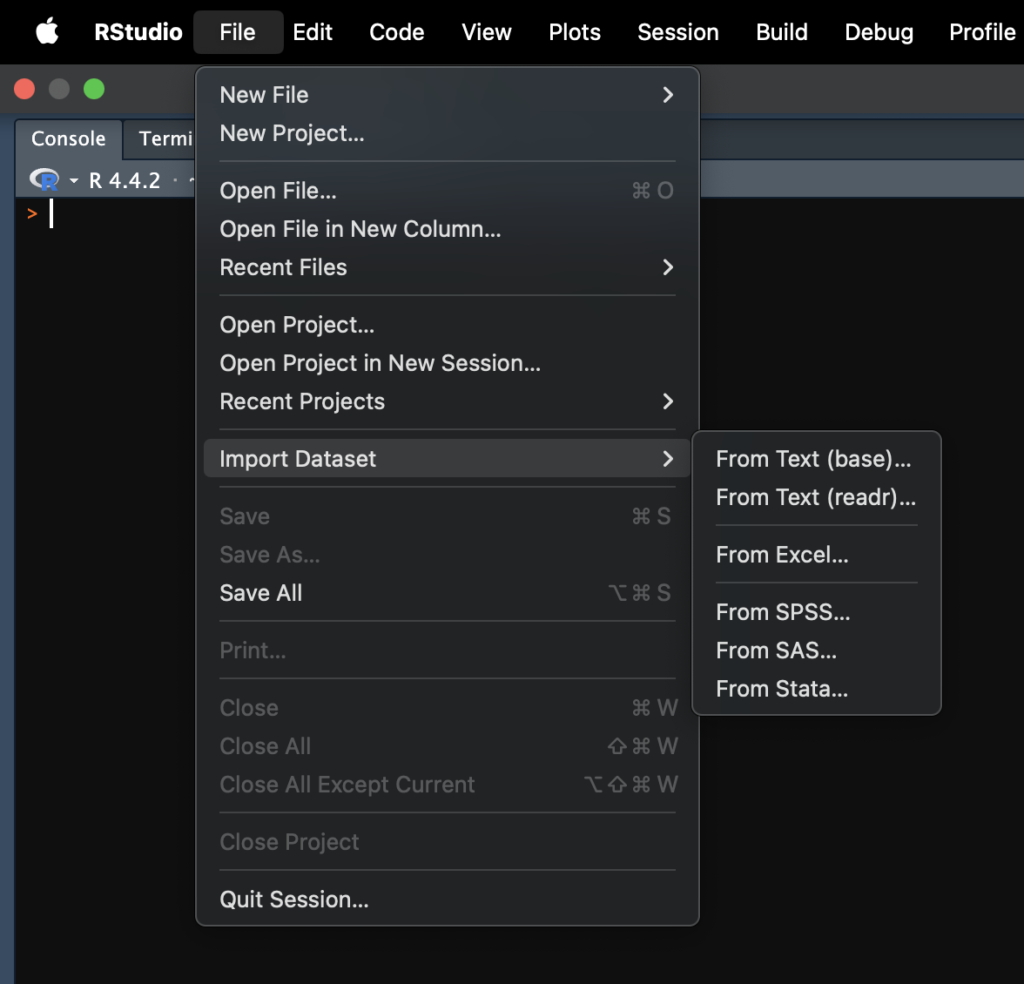
- RStudio で「環境タブ」を開く
- 「Import Dataset」→「From Text (base)」や「From Excel」など
- ファイルを選択し、「Import」
クリップボードからデータを読み込む
Excelや他のソフトウェアからデータをコピーし、Rに貼り付けることも可能です。
# クリップボードからデータを読み込む(Windows)
df <- read.table("clipboard")# クリップボードからデータを読み込む(macOS)
df <- read.table(pipe("pbpaste"))WindowsとmacOSではクリップボードからデータの取得方法が異なるので注意が必要です。
GUIやクリップボードを使うデータの読み込みは簡単で良いのですが、分析の再現性を考えるとパスを指定する方法を使った方が良い気がします。
まとめ
- データの形式
- データフレーム・TXT・CSV・TSV・Excelなど
- データフレームの特徴
- データフレームの作成方法と、要素の操作
- データの入力の注意点
- 縦長データで入力・余計な空白は作らない
- データの読み込み
read.table()・read.delim()・read.csv()関数などで読み込み
今回は、データの入力について説明してきました。
データの形式に合わせた読み込み方法で分析の準備を進めましょう。
次回は、Rで作図する方法について紹介します。
最後に、実際に私が購入したおすすめできる本を厳選して紹介します。
アフィリエイトリンクを使っていますが、クリックしていただけると更新の励みになります。よろしければぜひご覧ください!

Rによる統計解析 単行本 – 2009/4/1
実際のコードや技法が詰め込まれたわかりやすい書籍です。
Rで統計解析をするときの辞書的な本として愛用しています。

実験で使うとこだけ生物統計1 キホンのキ 決定版 単行本 – 2024/7/25
統計解析の基礎をわかりやすく解説している本です。
難しい用語や数式が少ないので、統計初心者におすすめです。

実験で使うとこだけ生物統計2 キホンのホン 決定版 単行本 – 2024/7/25
キホンのキに続き、統計検定の本質から検定法を説明している書籍です。
実験計画を立てる前におすすめしたい一冊です。