

研究室に配属されたばかりの新入生や、これからRで統計分析を始めたいと思っている方へ向けて、【R講座】では、RとRStudioの基本的な使い方から統計手法の選び方、基本的なデータ分析方法を解説しています。特にRが初めての方でも安心して学べるように、RStudioのクリック操作も紹介していきます。実際のコード例を交えながら進めるので、これからの研究やデータ分析に、役立てていただけたら嬉しいです。
この記事では、Tukey-Kramerの多重比較の方法について解説しています。
Tukey-Kramerの多重比較とは
Tukey-Kramerの多重比較検定(Tukey's HSD:Honest Significant Difference)は、複数のグループ間の平均値の差を全群比較するための方法です。これにより、どのグループ間の平均値が統計的に有意に異なるかを明らかにすることができます。
前提条件
Tukey-Kramerの多重比較を実施する際には以下の条件を確認します。
- 正規性:データが正規分布に従っていること。
- 等分散性:2つの群のデータが等分散であること。
- 群数:3群以上。
- データ尺度:データが間隔尺度または比率尺度であること。
仮説の設定
Tukey-Kramerの多重比較では次の仮説を設置し、全群で比較を行います。
- 帰無仮説(H0):2つの群の平均に差はない。
- 対立仮説(H1):2つの群の平均に差がある。
分散分析との違い
分散分析では、全体のF値とp値を計算し、グループ間に差があるかどうかを確認します。一方、多重比較では、具体的にどのグループ間に有意差があるかを検定します。つまり、分散分析表が全体の差異を確認するのに対し、多重比較は個々の差異を確認するためのものです。
分散分析の結果を見てから、事後検定としてTukeyの多重比較を行うこともありますが、検定の多重性問題に注意が必要です。
Tukey-Kramerの多重比較の関数と引数オプション
RでTukey-Kramerの多重比較を行うには、TukeyHSD()関数を使用します。
この関数は次のような引数があります。
TukeyHSD(x, which, ordered = FALSE, conf.level = 0.95, ...)x: 適合したモデルオブジェクト、通常はaovでフィットされたもの。which: 適合したモデル内の用語をリストする文字ベクトル。デフォルトはすべての用語。ordered: ファクターのレベルをサンプル内の平均値の増加順に並べるかどうかを示す論理値。orderedがTRUEの場合、計算された平均の差はすべて正の値になります。有意な差は、下限点が正の値であるものです。conf.level: 使用するファミリー全体の信頼水準を示す、0から1の間の数値。
分析の実践
- STEP 1データの読み込み
csvファイルからデータを読み込みます。
- STEP 2データの型変換(キャスト)
読み込んだデータの要因データを、Factor型に変更します。
- STEP 3Tukey-Kramerの多重比較を実行
TukeyHSD()関数で分散分析を実行します。 - STEP 4結果の出力
計算された結果がコンソールペインに出力されます。
使用するデータ
次のデータを使用します。
このcsvファイルには次のデータが含まれています。
| Temperature (°C) | Height (cm) | Weight (g) |
|---|---|---|
| 25 | 11.408563356834 | 34.032819857028 |
| 25 | 9.45823963789889 | 54.9096737259706 |
| 25 | 10.2786647241064 | 54.2160336538475 |
| 25 | 9.8060272553297 | 68.739038985953 |
| 25 | 11.5761581812187 | 60.3451432394433 |
| 25 | 8.52445236473948 | 50.8181031035401 |
| 25 | 9.85539179268946 | 49.1747623798284 |
| 25 | 8.92498980918183 | 56.060734308621 |
| 25 | 10.4065427319449 | 41.125798546829 |
| 25 | 12.2292622016409 | 51.0542139019377 |
| 30 | 13.4855029917497 | 103.528744733185 |
| 30 | 14.938292577988 | 105.503933584551 |
| 30 | 14.852729209961 | 88.6566903148316 |
| 30 | 16.541593068827 | 114.623515387464 |
| 30 | 14.0181443311961 | 107.021167106676 |
| 30 | 15.4965781726617 | 125.071111484834 |
| 30 | 16.6969478807231 | 81.0997285637598 |
| 30 | 14.7392636914319 | 94.1018720980883 |
| 30 | 14.2940714143323 | 82.8549770315418 |
| 30 | 14.8388214938277 | 95.790021021833 |
| 35 | 15.5013218277237 | 78.1014137650469 |
| 35 | 13.9864603295052 | 92.025705860145 |
| 35 | 16.6147522354681 | 70.5661519563607 |
| 35 | 15.0056419848525 | 63.0140291668191 |
| 35 | 12.0951009396544 | 71.926190857745 |
| 35 | 13.8928351810313 | 81.2105420273818 |
| 35 | 16.5475669326183 | 76.8190219140427 |
| 35 | 14.0231696496533 | 88.1840093119247 |
| 35 | 14.8984965523683 | 72.0109068656934 |
| 35 | 15.0426502497967 | 58.5177825784117 |
データの読み込み
まずは、次のコードを使って、オブジェクト「data」にread.csv()関数でcsvファイルのデータを代入します。
# データの読み込み
data <- read.csv(file.choose(),
check.names = F)csvファイルの読み込みでは、パスを指定することもできますが、今回はfile.choose関数でファイルを選択する方法をとっています。
データの整理
次に、データの因子変換をします。
Rでは説明変数をFactor型のデータとします。今回の分析ではTemperature (°C)を説明変数とするので、as.factor()関数でデータ型をinteger型からFactor型に変更します。
# 説明変数をデータ型をFactor型に変更
data$`Temperature (°C)` <- as.factor(data$`Temperature (°C)`)実行結果は、Environmentタブで確認できます。Temperature (°C)のデータ型がinteger型(左図)からFactor型(右図)に変わります。
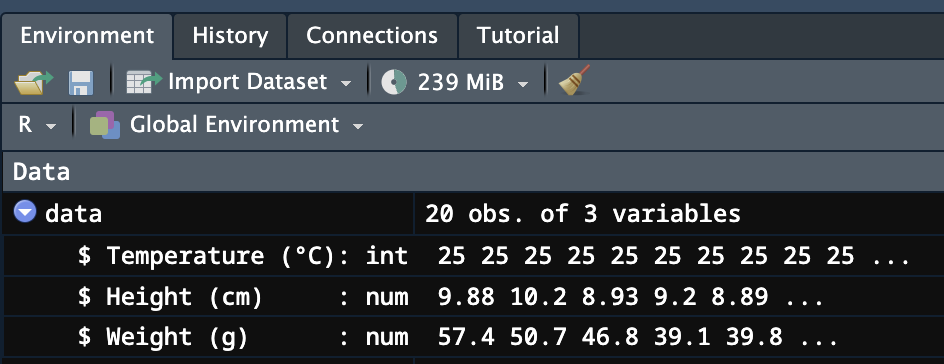
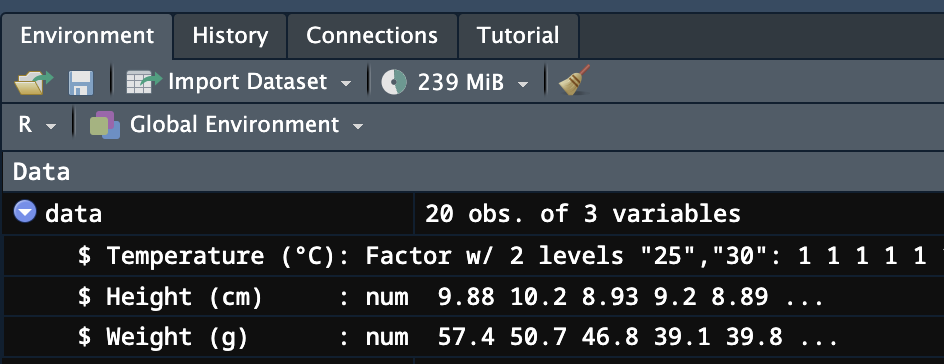
ここで、バッククォート「`」について、少しだけ補足します。
R言語においてバッククォート「 ` 」で文字列を挟むと、通常は予約語や空白、特殊文字を含む名前を使うことができます。これにより、通常は無効な識別子として扱われる文字列を有効なオブジェクト名として扱うことができます。
ヘッダー名であるHeight (cm)は、スペース「 」や括弧「()」が含まれているため、そのままオブジェクト名として使用できませんが、バッククォートを使うことでオブジェクト名として使用できます。
検定の実行
# Tukeyの多重比較
TukeyHSD(aov(data$`Height (cm)` ~ data$`Temperature (°C)`))結果の出力
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = data$`Height (cm)` ~ data$`Temperature (°C)`)
$`data$`Temperature (°C)``
diff lwr upr p adj
30-25 4.7433653 3.419748 6.066982 0.000000
35-25 4.5139704 3.190353 5.837587 0.000000
35-30 -0.2293949 -1.553012 1.094222 0.903592有意水準が5%とするとき、p値が0.05より小さい場合に帰無仮説を棄却し、2つの群の平均値に有意な差があると結論づけます。
今回の例では、30-25と35-25に有意差があり、35-30に有意差が検出できない結果となりました。
多重比較の結果にアルファベットを振る
Tukeyの多重比較の結果にアルファベットを振る方法はいくつかありますが、今回はmultcompパッケージを使った方法を紹介します。
multcompパッケージをインストール
multcompパッケージを使うと、多重比較の結果に添字をつけることができます。
初めてこのパッケージを使う場合は、install.packages("multcomp")でインストールを行います。次回以降はlibrary(multcomp)で起動します。
# 必要なパッケージの読み込み
install.packages("multcomp")
library(multcomp)アルファベットの出力
アルファベットの出力はaov()とglht()とcld()関数を使います。
次の流れで関数を使います。
aov()で分散分析モデル → glht()で比較方法を選択 → cld()でアルファベットの出力
# 分散分析のモデル
anova_result <- aov(data$`Height (cm)` ~ data$`Temperature (°C)`, data = data)
# 一般線形仮説検定と多重比較の方法を設定
glht_result <- glht(anova_result, linfct = mcp("data$`Temperature (°C)`" = "Tukey"))
# アルファベットの出力
cld(glht_result, decreasing = FALSE, level = 0.05)decreasingオプションで昇順か降順を設定できます。levelの値で有意水準を設定できます。
結果の見方
25 30 35
"a" "b" "b" cld()関数を使うことで、各グループがどのように分類されるかを視覚的に確認できます。添字が同じグループ同士は有意差がないことを示します。
今回の分析の結果は、30-25と35-25に有意差があり、35-30に有意差が検出できない結果となりました。
まとめ
今回は多重比較について紹介しました。
配布したcsvデータにはWeight (g)のデータもあるので、コードを書き換えて練習してみてください。
# データの読み込み
data <- read.csv(file.choose(),
check.names = F)
# 説明変数をデータ型をFactor型に変更
data$`Temperature (°C)` <- as.factor(data$`Temperature (°C)`)
# Tukeyの多重比較
TukeyHSD(aov(data$`Height (cm)` ~ data$`Temperature (°C)`))次回はマンホイットニーのU検定の方法について紹介します。

