
この記事では、Rでsource関数を使ったソースコードの読み込みと実行方法について詳しく説明します。
ソースコードとは
ソースコードは、プログラムの設計図です。Rのソースコードは、通常.Rファイルに保存されます。このファイルを読み込んで実行することで、プログラムを動かすことができます。例えば、データを分析するRスクリプトを作成し、それをソースコードとして保存することができます。
source関数と引数オプション
source関数は、外部のRスクリプトファイルを読み込み、実行するための関数です。
次のような構成になっています。
source(file, local = FALSE, echo = verbose, print.eval = echo,
exprs, spaced = use_file,
verbose = getOption("verbose"),
prompt.echo = getOption("prompt"),
max.deparse.length = 150, width.cutoff = 60L,
deparseCtrl = "showAttributes",
chdir = FALSE,
encoding = getOption("encoding"),
continue.echo = getOption("continue"),
skip.echo = 0, keep.source = getOption("keep.source"))- file:読み込むファイルまたはURLのパスを指定します。文字列または接続オブジェクトを指定できます。
stdin()接続は対話モードでコンソールから読み込みます。 - local
:TRUE、FALSE、または環境を指定します。解析された式が評価される場所を決定します。デフォルトのFALSEはユーザーのワークスペース(グローバル環境)を意味し、TRUEはsourceが呼び出された環境を意味します。 - echo:論理値。
TRUEの場合、各式が解析後、評価前に表示されます。 - print.eval:論理値。
TRUEの場合、各式の評価結果が表示されます。デフォルトはechoの値です。 - exprs
:source()およびwithAutoprint(*, evaluated=TRUE)の場合、ファイルを指定する代わりに式、呼び出し、または呼び出しのリストを指定しますが、評価されていない「式」は指定できません。 - spaced:論理値。
echo = TRUEの場合、各式の前に改行(空行)を表示するかどうかを指定します。 - verbose:論理値。
TRUEの場合、解析と評価の間に追加の診断情報が表示されます。 - prompt.echo:文字列。
echo = TRUEの場合に使用されるプロンプトを指定します。 - max.deparse.length
整数。echoがTRUEの場合に使用され、1つの式のデパース結果の最大文字数を指定します。 - width.cutoff:整数。ソース参照がない場合に
deparse()に渡されます。 - deparseCtrl:文字ベクトル。
deparse()に制御として渡されます。Rバージョン3.3.x以下では"showAttributes"にハードコーディングされていましたが、現在はデフォルトです。 - chdir:論理値。
TRUEの場合、fileがパス名であるときにRの作業ディレクトリが一時的にファイルを含むディレクトリに変更されます。 - encoding:文字ベクトル。
fileが文字列の場合に仮定されるエンコーディングを指定します。可能な値には"unknown"が含まれ、エンコーディングが推測されます。 - continue.echo:文字列。
echo = TRUEの場合に使用される継続行のプロンプトを指定します。 - skip.echo:整数。
echo = TRUEの場合にファイルの先頭でスキップされるコメント行の数を指定します。 - keep.source:論理値。可能な場合に、式をエコーする際にソースフォーマットを保持するかどうかを指定します。
実行例
csvのサンプル
このファイルには、日数と植物の高さに関するデータが含まれています。
Day,Height
1,2.5
2,3.0
3,3.6
4,4.1
5,4.8
6,5.4
7,6.0
8,6.5
9,7.1
10,7.6ソースファイルのサンプル
次に、上記のデータを分析するRスクリプトplant_growth_analysis.Rを作成します。
# plant_growth_analysis.R
# データの読み込み
plant_data <- read.csv("plant_growth.csv")
# データの要約
summary(plant_data)
# 成長曲線のプロット
plot(plant_data$Day, plant_data$Height, type = "l", col = "green",
xlab = "Day", ylab = "Height (cm)", main = "Plant Growth Over Time")
# 成長の傾向を示す線形回帰モデルのフィッティング
fit <- lm(Height ~ Day, data = plant_data)
abline(fit, col = "red")
# 回帰モデルの要約
summary(fit)このスクリプトは、以下のことを行います:
plant_growth.csvファイルからデータを読み込みます。- データの要約を表示します。
- 日ごとの植物の高さをプロットし、成長曲線を描きます。
- 成長の傾向を示す線形回帰モデルをフィッティングし、回帰直線をプロットに追加します。
- 回帰モデルの要約を表示します。
.Rファイルを読み込んで実行
次に、source関数を使ってコードを実行します。
# plant_growth_analysis.Rというファイルを読み込んで実行
source("plant_growth_analysis.R", echo = TRUE)実行結果
Day Height
Min. : 1.00 Min. :2.500
1st Qu.: 3.25 1st Qu.:3.725
Median : 5.50 Median :5.100
Mean : 5.50 Mean :5.060
3rd Qu.: 7.75 3rd Qu.:6.375
Max. :10.00 Max. :7.600 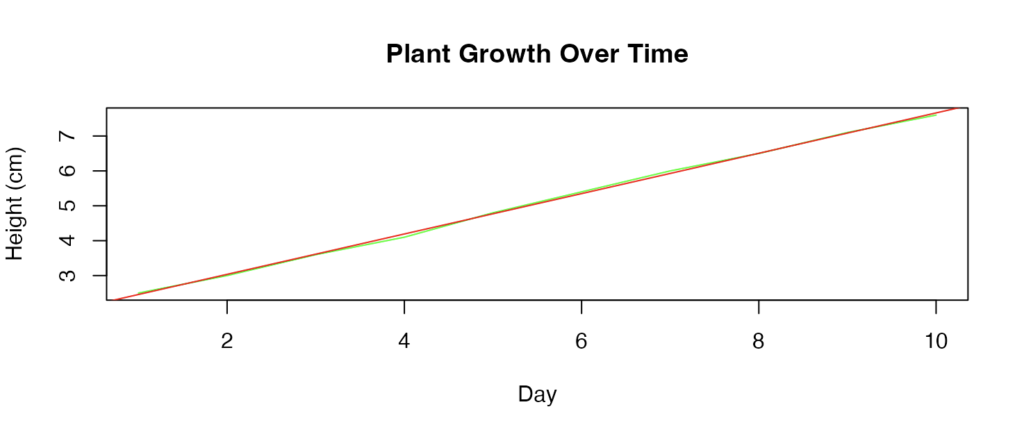
Call:
lm(formula = Height ~ Day, data = plant_data)
Residuals:
Min 1Q Median 3Q Max
-0.092727 -0.030909 0.005455 0.038636 0.072727
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.880000 0.037979 49.50 3.07e-11 ***
Day 0.578182 0.006121 94.46 1.76e-13 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.0556 on 8 degrees of freedom
Multiple R-squared: 0.9991, Adjusted R-squared: 0.999
F-statistic: 8923 on 1 and 8 DF, p-value: 1.761e-13このように、データの要約と成長曲線のプロット・回帰モデルの要約が表示されます。
この記事では、Rでのソースコードの読み込みと実行方法について詳しく紹介しました。
少しでもお役に立てたら嬉しいです。