
屋外の光環境を手軽に測定したいと思い、スペクトルメーター「YT001P」を購入しました。
研究用途の分光器は高価なものが多いですが、YT001Pは比較的手の届きやすい価格帯。それでも決して安い買い物ではありませんが、「ポータブルで持ち運びやすい」「スペクトル・PPFDを測定できる」という点に魅力を感じました。
今回は実際に使用してみたレビューと、保存したCSVデータをRのggplot2で可視化する方法を紹介します。
YT001Pを購入した理由
屋外で植物の生育環境や照明環境を調べるために、持ち運び可能なスペクトルメーターを探していました。
求めていた条件は以下の通りです。
- ポータブルで持ち運びやすい
- 比較的安価
- スペクトルデータを取得できる
- PCでデータ解析できる
Amazonで見つけて購入しましたが、中国からの発送だったため、到着まで約2週間かかりました。
開封

箱から取り出して内容物を確認します。
収納袋に入っていました。

- 本体
- 収納袋
- 充電器とケーブル(A to C)
- 品質保証書
- 品質検査証

本体は想像以上にしっかりしており、金属製で堅牢な印象です。
本体の特徴

- センサーは本体上部
- 側面にスイッチが1つ
- 長押しで起動・終了
- USB-Cポート搭載
操作の大部分はタッチパネルで行います。
画面構成
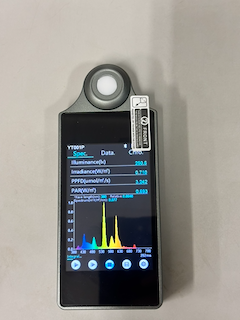
画面上部には以下のタブがあります。
- Spec
- Data
- Chro
画面下部には以下の操作ボタンがあります。
- 連続測定
- 単発測定
- 測定停止
- データ保存
- 設定
直感的なUIで、説明書を読まなくてもある程度操作できました。
単色LEDを測定してみる

まずは手元にあった単色LEDを測定してみました。
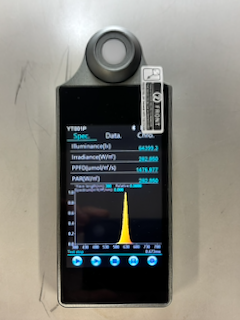
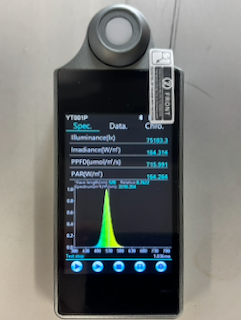

| LED | 主波長 |
|---|---|
| 赤 | 約620 nm |
| 緑 | 約520 nm |
| 青 | 約460 nm |
測定結果は概ね期待通りでした。
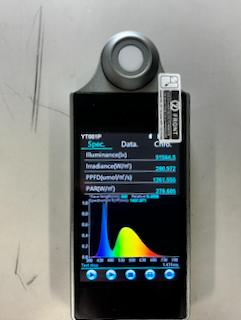
また白色LEDを測定すると、
- 青色LED由来のピーク
- 蛍光体由来の広いピーク
が確認できました。
典型的な青色LED+蛍光体による白色LEDのスペクトル形状であり、スペクトルメーターとして最低限の性能は十分ありそうです。
データ保存機能

メニューを見る限り、
- CSV
の2種類で保存できるようです。
今回はCSV形式で保存しました。
ファイル名を付けて保存できるため、後で整理しやすいのは便利です。
何度試してもPDFファイルは保存されませんでした。
私の個体だけなのか、ファームウェアの問題なのか、それとも未実装機能なのかは不明です。
普段はCSVしか使わないので大きな問題ではありませんが、購入を検討している方は注意が必要です。
データ読み込み
Macでデータを読み出そうとして苦戦
測定後、Macに接続してデータを取り出そうとしました。
USB-Cケーブルで接続すると……
何も認識されません。
薄々予感はしていましたが、ストレージとしてマウントされない状態です。
「もしかして故障?」と危惧しました。
Windowsでは問題なく認識
Windows PCに接続してみたところ、無事認識されました。
内部には以下のファイルが保存されています。
- Androidアプリ
- Windows用PCソフト(.exe)
- 説明書
- 保存した測定データ
故障ではなかったので一安心です。
Macで再挑戦
その後いろいろ試した結果、
- USB-C to USB-C → 認識しない
- USBハブ経由(USB-A to USB-C)→ 認識する
という謎の挙動を確認しました。
なぜ認識するのかは分かりませんが、とりあえずMacでもデータ取得は可能でした。
Macユーザーは少し苦労するかもしれません。
なお、付属のPCソフトはWindows専用です。
CSVデータをggplot2で可視化
CSVデータが取得できたので、Rで可視化してみます。
定番ですが、やはりggplot2が便利です。
コード
YT001Pの出力するCSVに合わせて作図するコードです。
YT001P(ファイルパス)で自動的に作図します。
引数outputで
- spc: スペクトル分布図
- rgb: RGB比
- cum: 積み上げPPFD
- all: 全データをまとめた図
を出力します。
YT001P <- function(file_path,
output = "all" # "spc", "rgb", "cum"
){
# パッケージ
library(ggplot2)
library(dplyr)
library(gridExtra)
library(grid)
# NULL前処理
read_nullbyte_csv <- function(path) {
con <- file(path, "rb")
raw_data <- readBin(con, what = "raw", n = 2e6) # 最大2MB読み込み
close(con)
raw_data <- raw_data[raw_data != as.raw(0x00)] # NULLバイト除去
txt <- rawToChar(raw_data) # raw → 文字列
lines <- strsplit(txt, "\n")[[1]] # 行分割
lines <- trimws(lines) # 前後空白除去
lines <- lines[nchar(lines) > 0] # 空行除去
lines
}
lines <- read_nullbyte_csv(file_path)
# データフレーム変換
parse_kv <- function(lines) {
# 最後のカンマ位置を検索
last_comma <- regexpr(",[^,]*$", lines)
has_comma <- last_comma > 0
lines <- lines[has_comma]
lc <- last_comma[has_comma]
key <- trimws(substring(lines, 1L, lc - 1L))
value <- trimws(substring(lines, lc + 1L))
data.frame(key = key, value = value, stringsAsFactors = FALSE)
}
kv <- parse_kv(lines)
# スペクトルデータ抽出
spec_mask <- grepl("^\\d{3}\\(mW/m2/nm\\)$", kv$key) # キーが "NNN(mW/m2/nm)" の行を抽出
spec_df <- kv[spec_mask, ] |>
transmute(
wavelength = as.integer(sub("\\(mW/m2/nm\\)", "", key)),
irradiance = as.numeric(value)
) |>
arrange(wavelength)
# メタデータ抽出
get_meta <- function(kv, pattern) {
idx <- grep(pattern, kv$key, perl = TRUE)
if (length(idx) == 0) return(NA_real_)
suppressWarnings(as.numeric(kv$value[idx[1]]))
}
meta <- list(
CCT = get_meta(kv, "CCT\\(K\\)"),
illuminance = get_meta(kv, "Illuminance\\(lx\\)"),
PPFD = get_meta(kv, "PPFD\\(umol"), # 400–780
PPFD400700 = get_meta(kv, "PPFD400-700"),
YPFD = get_meta(kv, "YPFD"),
PAR = get_meta(kv, "PAR\\(W/m2\\)"),
PUR = get_meta(kv, "PUR\\(W/m2\\)"),
irrad = get_meta(kv, "Irradiance\\(W/m2\\)"),
Ra = get_meta(kv, ",Ra$"),
SP = get_meta(kv, "S/P"),
peak_wl = get_meta(kv, "PeakWave"),
centroid_wl = get_meta(kv, "CentroidWave"),
half_width = get_meta(kv, "HalfWidth"),
R_ratio = get_meta(kv, "R-ratio"),
G_ratio = get_meta(kv, "G-ratio"),
B_ratio = get_meta(kv, "B-ratio"),
date_str = sub("Date,", "", grep("^Date,", lines, value=TRUE)[1]),
time_str = sub("Time,", "", grep("^Time,", lines, value=TRUE)[1])
)
# 光合成光量子数への換算
# E [mW/m²/nm] × 1e-3 [W] × λ [m] / (h·c·Na) × 1e6 → µmol/m²/s/nm
h <- 6.62607e-34 # プランク定数 [J·s]
c_l <- 2.99792e8 # 光速 [m/s]
Na <- 6.02214e23 # アボガドロ数 [/mol]
spec_df <- spec_df |>
mutate(
ppfd_density = irradiance * 1e-3 * (wavelength * 1e-9) / (h * c_l * Na) * 1e6
)
par_df <- spec_df |>
filter(wavelength >= 400, wavelength <= 700) |>
mutate(
cum_ppfd = cumsum(ppfd_density),
cum_pct = cum_ppfd / sum(ppfd_density) * 100
)
# 波長近似RGB色
wavelength_to_hex <- function(wl) {
vapply(wl, function(w) {
# 各チャンネルを0-1で計算し、最後にrgb()へ渡す
if (w < 380) {
# 380nm以下: ほぼ黒
rgb(0.04, 0, 0.06)
} else if (w < 400) {
# UV帯(380-400nm): 黒に近い暗紫 → 紫
# 380: (0.04,0,0.06) → 400: (0.38,0,0.82)
t <- (w - 380) / 20
rgb(0.04 + t * 0.34,
0,
0.06 + t * 0.76)
} else if (w < 440) {
# 紫-青紫帯(400-440nm): (0.38,0,0.82) → (0,0,1)
t <- (w - 400) / 40
rgb(0.38 * (1 - t),
0,
0.82 + t * 0.18)
} else if (w < 490) {
# 青帯(440-490nm): (0,0,1) → (0,1,1)
t <- (w - 440) / 50
rgb(0,
t,
1)
} else if (w < 510) {
# 青緑帯(490-510nm): (0,1,1) → (0,1,0)
t <- (w - 490) / 20
rgb(0,
1,
1 - t)
} else if (w < 570) {
# 緑帯(510-570nm): (0,1,0) → (0.85,1,0)
t <- (w - 510) / 60
rgb(t * 0.85,
1,
0)
} else if (w < 590) {
# 黄帯(570-590nm): (0.85,1,0) → (1,0.75,0)
t <- (w - 570) / 20
rgb(0.85 + t * 0.15,
1 - t * 0.25,
0)
} else if (w < 625) {
# 橙帯(590-625nm): (1,0.75,0) → (1,0.10,0)
t <- (w - 590) / 35
rgb(1,
0.75 - t * 0.65,
0)
} else if (w < 700) {
# 赤帯(625-700nm): (1,0.10,0) → (0.75,0,0)
t <- (w - 625) / 75
rgb(1 - t * 0.25,
0.10 * (1 - t),
0)
} else if (w <= 780) {
# FR帯(700-780nm): 深赤 → 暗茶 → ほぼ黒
# 700: (0.75,0,0) → 740: (0.35,0.07,0) → 780: (0.08,0.02,0)
t <- (w - 700) / 80
# 二段階: 前半で茶色みを加え、後半で黒へ
r <- 0.75 * (1 - t)^1.6 + 0.08 * t
g <- 0.10 * sin(pi * t * 0.7) # 茶色の中間でわずかな緑成分
rgb(max(0, min(1, r)),
max(0, min(1, g)),
0)
} else {
rgb(0.05, 0.01, 0) # 780nm超
}
}, character(1))
}
spec_rect <- spec_df |> # スペクトル塗りつぶし用(geom_rect: 各1nm幅リボン)
filter(wavelength >= 380, wavelength <= 780) |>
mutate(
col = wavelength_to_hex(wavelength),
xmin = wavelength - 0.5,
xmax = wavelength + 0.5
)
# スペクトル分布図
ymax <- max(spec_df$irradiance) * 1.12
p_spec <- ggplot() +
# 波長帯背景
annotate("rect", xmin=380, xmax=400, ymin=0, ymax=Inf, fill="#8800CC", alpha=.08) +
annotate("rect", xmin=400, xmax=500, ymin=0, ymax=Inf, fill="#2244FF", alpha=.07) +
annotate("rect", xmin=500, xmax=600, ymin=0, ymax=Inf, fill="#00AA22", alpha=.07) +
annotate("rect", xmin=600, xmax=700, ymin=0, ymax=Inf, fill="#FF2200", alpha=.07) +
annotate("rect", xmin=700, xmax=780, ymin=0, ymax=Inf, fill="#660000", alpha=.05) +
# 波長帯ラベル
annotate("text", x=390, y=ymax*.975, label="UV", size=3, color="#6600AA", fontface="bold", vjust=1) +
annotate("text", x=450, y=ymax*.975, label="Blue", size=3, color="#0033CC", fontface="bold", vjust=1) +
annotate("text", x=550, y=ymax*.975, label="Green", size=3, color="#006600", fontface="bold", vjust=1) +
annotate("text", x=650, y=ymax*.975, label="Red", size=3, color="#AA0000", fontface="bold", vjust=1) +
annotate("text", x=740, y=ymax*.975, label="FR", size=3, color="#550000", fontface="bold", vjust=1) +
# 虹色リボン塗りつぶし
geom_rect(data = spec_rect,
aes(xmin=xmin, xmax=xmax, ymin=0, ymax=irradiance, fill=I(col)),
alpha = 0.82, color = NA) +
# スペクトル輪郭
geom_line(data = spec_df |> filter(wavelength >= 380, wavelength <= 780),
aes(x=wavelength, y=irradiance),
color = "#111111", linewidth = 0.5) +
# 軸・スケール
scale_x_continuous(
name = "Wavelength (nm)",
breaks = seq(380, 780, 40),
limits = c(380, 780),
expand = c(0, 0)
) +
scale_y_continuous(
name = expression(bold(paste("Spectral irradiance (mW·m"^{-2},"·nm"^{-1},")"))),
limits = c(0, ymax),
breaks = pretty(c(0, ymax), n = 6),
expand = c(0, 0)
) +
theme_classic(base_size = 11) +
theme(
plot.title = element_text(face="bold", size=12, hjust=0),
plot.subtitle = element_text(size=8.5, color="gray40"),
axis.title = element_text(size=10, face="bold"),
axis.text = element_text(size=9),
panel.border = element_rect(color="black", fill=NA, linewidth=0.8),
plot.margin = margin(8, 14, 4, 8)
) +
labs(
title = "Spectral Power Distribution",
subtitle = paste0(
"CCT = ", round(meta$CCT), " K",
" | Ra = ", round(meta$Ra, 1),
" | S/P = ", round(meta$SP, 2),
" | Peak = ", round(meta$peak_wl, 1),
" | Centroid = ", round(meta$centroid_wl, 1),
" | Half-width = ", round(meta$half_width, 1), " nm"
)
)
# RGB比率図
rgb_df <- data.frame(
band = factor(
c("Blue\n400–500 nm", "Green\n500–600 nm", "Red\n600–700 nm"),
levels = c("Blue\n400–500 nm", "Green\n500–600 nm", "Red\n600–700 nm")
),
ratio = c(meta$B_ratio, meta$G_ratio, meta$R_ratio)
)
p_rgb <- ggplot(rgb_df, aes(x=band, y=ratio, fill=band)) +
geom_col(width=0.55, color="white", linewidth=0.6) +
geom_text(aes(label=paste0(round(ratio, 1), "%")),
vjust=-0.4, size=3.8, fontface="bold", color="#222222") +
scale_fill_manual(
values = c("#3355BB","#228833","#BB2211"), guide="none"
) +
scale_y_continuous(limits=c(0, 100), breaks=seq(0,100,10), expand=c(0,0)) +
labs(title="RGB Ratio", x=NULL, y="Fraction of irradiance (%)") +
theme_classic(base_size=10) +
theme(
plot.title = element_text(face="bold", size=11, hjust=0.5),
axis.title = element_text(size=10, face="bold"),
axis.text.x = element_text(face="bold"),
panel.border = element_rect(color="black", fill=NA, linewidth=0.7),
plot.margin = margin(8, 10, 4, 8)
)
# 累積PPFD(PAR域)
p_cum <- ggplot(par_df, aes(x=wavelength)) +
annotate("rect", xmin=400, xmax=500, ymin=-Inf, ymax=Inf, fill="#3355BB", alpha=.09) +
annotate("rect", xmin=500, xmax=600, ymin=-Inf, ymax=Inf, fill="#228833", alpha=.09) +
annotate("rect", xmin=600, xmax=700, ymin=-Inf, ymax=Inf, fill="#BB2211", alpha=.09) +
geom_area(aes(y=cum_pct), fill="#888888", alpha=0.30) +
geom_line(aes(y=cum_pct), color="#222222", linewidth=0.75) +
geom_hline(yintercept=50, linetype="dashed", color="#666666", linewidth=0.4) +
annotate("text", x=698, y=52.5, label="50%", size=2.9, color="#555555", hjust=1) +
scale_x_continuous(
name = "Wavelength (nm)",
breaks = seq(400, 700, 50),
limits = c(400, 702),
expand = c(0, 0)
) +
scale_y_continuous(
name = "Cumulative PPFD (%)",
limits = c(0, 105),
breaks = seq(0, 100, 25),
expand = c(0, 0)
) +
labs(title = "Cumulative PPFD (400–700 nm)") +
theme_classic(base_size=10) +
theme(
plot.title = element_text(face="bold", size=11, hjust=0),
axis.title = element_text(size=10, face="bold"),
panel.border = element_rect(color="black", fill=NA, linewidth=0.7),
plot.margin = margin(8, 10, 4, 8)
)
# 数値表
tab_df <- data.frame(
Parameter = c(
"ePPFD (380–780 nm)",
"PPFD (400–700 nm)",
"YPFD",
"PAR",
"PUR",
"Irradiance",
"Illuminance",
"CCT",
"Ra"
),
Value = c(
sprintf("%.3f", meta$PPFD),
sprintf("%.3f", meta$PPFD400700),
sprintf("%.3f", meta$YPFD),
sprintf("%.4f", meta$PAR),
sprintf("%.4f", meta$PUR),
sprintf("%.4f", meta$irrad),
sprintf("%.1f", meta$illuminance),
sprintf("%.0f", meta$CCT),
sprintf("%.1f", meta$Ra)
),
Unit = c(
"umol/m2/s", "umol/m2/s", "umol/m2/s",
"W/m2", "W/m2", "W/m2",
"lx", "K", "—"
),
stringsAsFactors = FALSE
)
# ttheme_minimal の hjust/x はセル順(列優先)で全セル分指定する必要がある
n_row <- nrow(tab_df) # 3列 × nrow(tab_df) 行 → 各列の値を行数分繰り返す
core_hjust <- rep(c(0, 1, 0), each = n_row) # col1:left, col2:right, col3:left
core_x <- rep(c(0.04, 0.96, 0.06), each = n_row)
tbl_theme <- ttheme_minimal(
core = list(
fg_params = list(
fontsize = 9.5,
hjust = core_hjust,
x = core_x
)
),
colhead = list(
fg_params = list(
fontsize = 10,
fontface = "bold",
hjust = c(0, 1, 0), # ヘッダーは3列のみなのでそのまま
x = c(0.04, 0.96, 0.06)
),
bg_params = list(fill = "#DDDDDD", col = NA)
)
)
p_table <- tableGrob(tab_df, rows=NULL, theme=tbl_theme)
# 出力
if (output == "all") {
layout_m <- rbind(c(1, 1, 1),
c(2, 3, 4))
p <- grid.arrange(
p_spec, p_rgb, p_cum, p_table,
layout_matrix = layout_m
)
}
if (output == "spc") {
p <- p_spec
}
if (output == "rgb") {
p <- p_rgb
}
if (output == "cum") {
p <- p_cum
}
return(grid.draw(p))
}2026-06-08:グラデーションを滑らかにする修正を行いました。
出力例
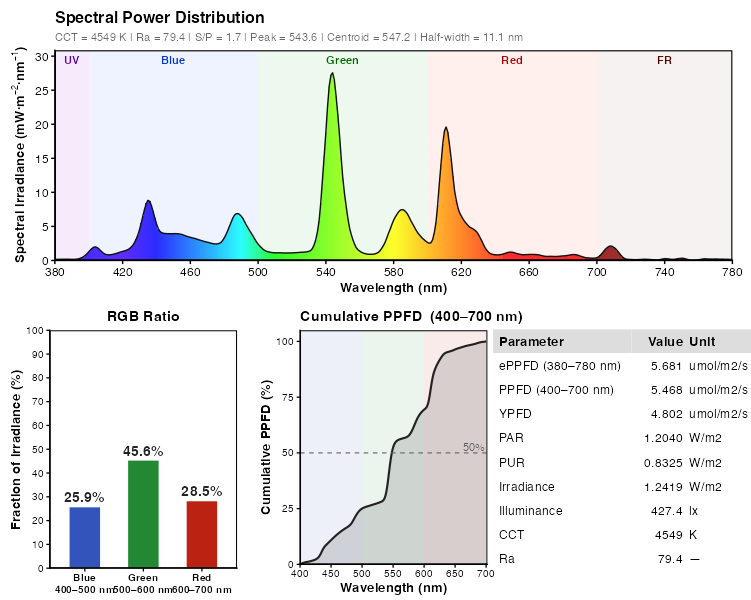
スペクトル分布がシンプルに可視化できます。
ピーク波長の確認や、異なる光源同士の比較もしやすくなります。
個人的にはこれくらいの表示ができれば十分実用的だと感じました。
YT001Pを実際に使った感想
使用してみた感想です。
良かった点
- スペクトルメーターとしては比較的安価
- 波長の読み取りは安定している
- 持ち運びしやすい
- CSV形式でデータを取得できる
- 測定項目が非常に多い
気になった点
- Macとの相性が微妙
- Windowsソフトしか用意されていない
- PDF保存ができない
- 光量が極端に弱い環境ではノイズが多い
まとめ|YT001Pはこんな人におすすめ
YT001Pは、研究用の高価な分光器ほどの性能は期待できないものの、
- 光環境を手軽に測定したい
- LEDスペクトルを確認したい
- 植物育成用ライトを評価したい
- CSVデータを解析したい
といった用途には十分実用的なスペクトルメーターだと感じました。
特にRやPythonでデータ解析を行う人にとっては、CSVでデータを取り出せる点が大きなメリットです。
Macユーザーは接続方法に少し工夫が必要ですが、安価にスペクトル測定を始めたい人には面白い選択肢ではないでしょうか。
Amazonアフィリエイトでブログ運営しています。
応援いただけると嬉しいです。

ネスカフェ 香味焙煎 ひとときの贅沢 スティック ブラック 20P,箱,レギュラー ソリュブル コーヒー,個包装

AHMAD TEA(アーマッドティー) クラシックセレクション ティーバッグ 20袋

