

研究室に配属されたばかりの新入生や、これからRで統計分析を始めたいと思っている方へ向けて、【R講座】では、RとRStudioの基本的な使い方から統計手法の選び方、基本的なデータ分析方法を解説しています。特にRが初めての方でも安心して学べるように、RStudioのクリック操作も紹介していきます。実際のコード例を交えながら進めるので、これからの研究やデータ分析に、役立てていただけたら嬉しいです。
この記事では、分散分析(ANOVA)について紹介しています。
分散分析(ANOVA)とは
分散分析(ANOVA)は、3つ以上の群の平均値に統計的な差があるかを検証する手法です。
分散分析の種類
分散分析には、いくつかの種類があります。
今回は代表的な次の分散分析を紹介します。
- 一元配置分散分析:1つの独立変数(因子)を持つ分散分析。
- 二元配置分散分析:2つの独立変数(因子)を持つ分散分析。
- 対応のある分散分析:同じ被験者を複数回測定したデータに対する分散分析。
これらの他にも、要因の水準数や組み合わせによってさまざまな分散分析の方法があります。分散分析の種類は、研究の目的に応じて適切なものを選択します。
前提条件
分散分析を行う前に、以下の条件を確認しましょう。
- 対応の有無:
- 対応のあるデータ:同じ対象の前後比較(例:同じ人のダイエット前後の体重)
- 対応のないデータ:異なる対象の比較(例:異なる人々のグループ間比較)
- 正規性:データが正規分布に従っているか。
- 等分散性:各群の分散が等しいか。
- 群数:3群以上。
- データ尺度:データが間隔尺度または比尺度であること。
仮説の設定
分散分析を行う前に、以下の仮説を設定します。
一元配置分散分析
- 帰無仮説(H0):全ての群の平均値は等しい。
- 対立仮説(H1):少なくとも1つの群の平均値が他と異なる。
二元配置分散分析
要因1と要因2にそれぞれ次の仮説を設定します。
- 帰無仮説(H0):全ての群の平均値は等しい。
- 対立仮説(H1):少なくとも1つの群の平均値が他と異なる。
また、要因1と要因2の交互作用について次の仮説を設置します。
- 帰無仮説(H0):要因1と要因2は互いに影響しあわない。
- 対立仮説(H1):要因1と要因2は互いに影響する。
以上の仮説に基づいて検定を行います。
分散分析の関数と引数オプション
Rで分散分析を行う方法はいくつかありますが、今回は、分散分析にaov()関数を使用する方法を紹介します。
以下がaov()関数の主な引数オプションです。
aov(formula, data = NULL, projections = FALSE, qr = TRUE, contrasts = NULL, ...)formula: 分析モデルの式(例:y ~ x)data: データフレームprojections: 投影行列を含むかどうかqr: QR分解を行うかどうかcontrasts: 対比の設定
分析の実践
- STEP 1データの読み込み
csvファイルからデータを読み込みます。
- STEP 2データの型変換(キャスト)
読み込んだデータの要因データを、Factor型に変更します。
- STEP 3分散分析の実行
summary()関数とaov()関数で分散分析を実行します。 - STEP 4結果の出力
計算された結果がコンソールペインに出力されます。
使用するデータ
今回は、次のcsvファイルを使用して説明します。
このcsvファイルには次のデータが含まれています。
| Temperature (°C) | Height (cm) | Weight (g) |
|---|---|---|
| 25 | 11.408563356834 | 34.032819857028 |
| 25 | 9.45823963789889 | 54.9096737259706 |
| 25 | 10.2786647241064 | 54.2160336538475 |
| 25 | 9.8060272553297 | 68.739038985953 |
| 25 | 11.5761581812187 | 60.3451432394433 |
| 25 | 8.52445236473948 | 50.8181031035401 |
| 25 | 9.85539179268946 | 49.1747623798284 |
| 25 | 8.92498980918183 | 56.060734308621 |
| 25 | 10.4065427319449 | 41.125798546829 |
| 25 | 12.2292622016409 | 51.0542139019377 |
| 30 | 13.4855029917497 | 103.528744733185 |
| 30 | 14.938292577988 | 105.503933584551 |
| 30 | 14.852729209961 | 88.6566903148316 |
| 30 | 16.541593068827 | 114.623515387464 |
| 30 | 14.0181443311961 | 107.021167106676 |
| 30 | 15.4965781726617 | 125.071111484834 |
| 30 | 16.6969478807231 | 81.0997285637598 |
| 30 | 14.7392636914319 | 94.1018720980883 |
| 30 | 14.2940714143323 | 82.8549770315418 |
| 30 | 14.8388214938277 | 95.790021021833 |
| 35 | 15.5013218277237 | 78.1014137650469 |
| 35 | 13.9864603295052 | 92.025705860145 |
| 35 | 16.6147522354681 | 70.5661519563607 |
| 35 | 15.0056419848525 | 63.0140291668191 |
| 35 | 12.0951009396544 | 71.926190857745 |
| 35 | 13.8928351810313 | 81.2105420273818 |
| 35 | 16.5475669326183 | 76.8190219140427 |
| 35 | 14.0231696496533 | 88.1840093119247 |
| 35 | 14.8984965523683 | 72.0109068656934 |
| 35 | 15.0426502497967 | 58.5177825784117 |
データの読み込み
まずは、次のコードを使って、オブジェクト「data」にread.csv()関数でcsvファイルのデータを代入します。
# データの読み込み
data <- read.csv(file.choose(),
check.names = F)csvファイルの読み込みでは、パスを指定することもできますが、今回はfile.choose関数でファイルを選択する方法をとっています。
データの整理
次に、データの因子変換をします。
Rでは説明変数をFactor型のデータとします。今回の分析ではTemperature (°C)を説明変数とするので、as.factor()関数でデータ型をinteger型からFactor型に変更します。
# 説明変数をデータ型をFactor型に変更
data$`Temperature (°C)` <- as.factor(data$`Temperature (°C)`)実行結果は、Environmentタブで確認できます。Temperature (°C)のデータ型がinteger型(左図)からFactor型(右図)に変わります。
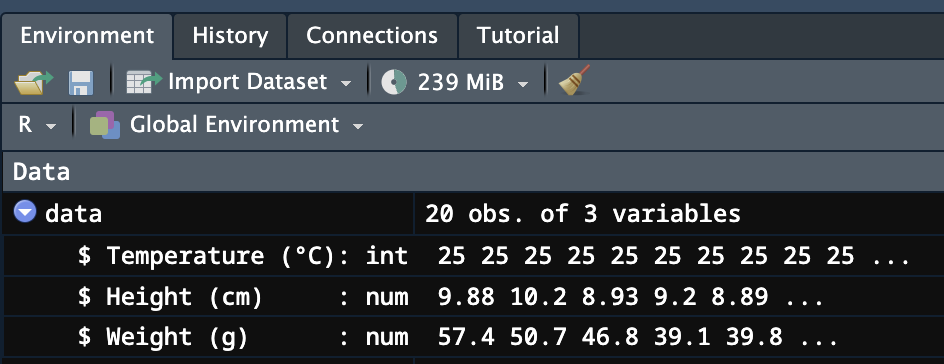
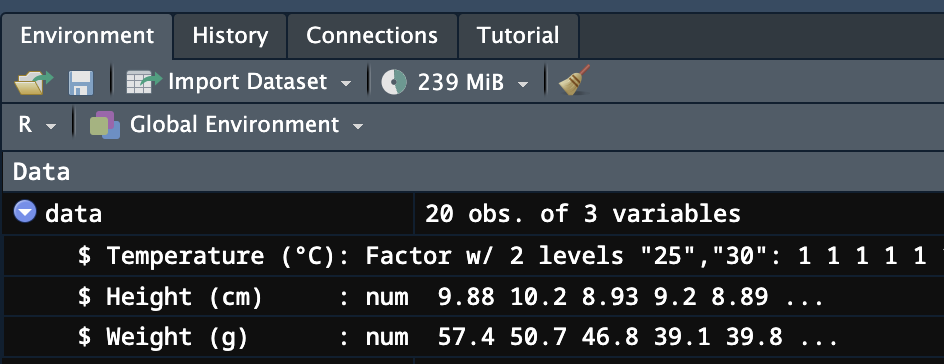
ここで、バッククォート「`」について、少しだけ補足します。
R言語においてバッククォート「 ` 」で文字列を挟むと、通常は予約語や空白、特殊文字を含む名前を使うことができます。これにより、通常は無効な識別子として扱われる文字列を有効なオブジェクト名として扱うことができます。
ヘッダー名であるHeight (cm)は、スペース「 」や括弧「()」が含まれているため、そのままオブジェクト名として使用できませんが、バッククォートを使うことでオブジェクト名として使用できます。
分散分析の実行
次に、以下のコードで分散分析を実行します。
# 一元配置分散分析
summary(aov(data$`Height (cm)` ~ data$`Temperature (°C)`))結果の出力
検定を実行した結果は、コンソールペインに表示されます。
Df Sum Sq Mean Sq F value Pr(>F)
data$`Temperature (°C)` 2 143.09 71.55 50.21 7.99e-10 ***
Residuals 27 38.47 1.42
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1有意水準が5%とするとき、p値(p-value)が0.05より小さい場合、帰無仮説を棄却し、2つの群の平均に有意な差があると結論づけます。
まとめ
今回はRを使用して分散分析を行う方法について解説しました。
# データの読み込み
data <- read.csv(file.choose(),
check.names = F)
# 説明変数をデータ型をFactor型に変更
data$`Temperature (°C)` <- as.factor(data$`Temperature (°C)`)
# 一元配置分散分析
summary(aov(data$`Height (cm)` ~ data$`Temperature (°C)`))配布したcsvデータにはWeight (g)のデータもあるので、コードを書き換えて練習してみてください。
その他の分散分析については、似たような感じになるのでここにメモしておきます。
oneway.test()関数を使うことで等分散を仮定できないときの一元配置分散分析を行えます。
等分散を仮定できるとき
# 一元配置分散分析(等分散を仮定)
oneway.test(data$`Height (cm)` ~ data$`Temperature (°C)`, var.equal = TRUE) One-way analysis of means
data: data$`Height (cm)` and data$`Temperature (°C)`
F = 50.211, num df = 2, denom df = 27, p-value = 7.992e-10有意水準が5%とするとき、p値(p-value)が0.05より小さい場合、帰無仮説を棄却し、2つの群の平均に有意な差があると結論づけます。
summary()とaov()を組み合わせた計算結果と同じになります。
等分散を仮定できないとき
# 一元配置分散分析(等分散を仮定しない)
oneway.test(data$`Height (cm)` ~ data$`Temperature (°C)`, var.equal = FALSE) One-way analysis of means (not assuming equal variances)
data: data$`Height (cm)` and data$`Temperature (°C)`
F = 50.411, num df = 2.000, denom df = 17.769, p-value = 4.741e-08有意水準が5%とするとき、p値(p-value)が0.05より小さい場合、帰無仮説を棄却し、2つの群の平均に有意な差があると結論づけます。
ウェルチの方法で分散分析が行われます。
対応のある一元配置分散分析
IDを追加した次のデータを使用します。
通常の一元配置分散分析のコードにError()関数を追加します。
summary(aov(目的変数 ~ 説明変数 + Error(ID/説明変数)))
# データ読み込み
data <- read.csv(file.choose(), check.names = FALSE)
# データの整理
data$`Temperature (°C)` <- as.factor(data$`Temperature (°C)`)
data$ID <- as.factor(data$ID)
# aov関数を使用して分散分析を実行
summary(aov(data$`Height (cm)` ~ data$`Temperature (°C)` + Error(data$ID/data$`Temperature (°C)`)))Error: data$ID
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 9 12.3 1.367
Error: data$ID:data$`Temperature (°C)`
Df Sum Sq Mean Sq F value Pr(>F)
data$`Temperature (°C)` 2 143.09 71.55 49.21 5.05e-08 ***
Residuals 18 26.17 1.45
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1有意水準が5%とするとき、p値(p-value)が0.05より小さい場合、帰無仮説を棄却し、2つの群の平均に有意な差があると結論づけます。
計算結果が変わるので、IDのデータ型をFactor型にしてください。
二元配置分散分析
次のデータを使用します。
二元配置分散分析は、一元配置分散分析のコードに説明変数を追加します。
summary(aov(目的変数 ~ 説明変数1 * 説明変数2))
# データ読み込み
data <- read.csv(file.choose(), check.names = FALSE)
# データの整理
data$`Temperature (°C)` <- as.factor(data$`Temperature (°C)`)
data$`Period (day)` <- as.factor(data$`Period (day)`)
# aov関数を使用して分散分析を実行
summary(aov(data$`Height (cm)` ~ data$`Temperature (°C)` * data$`Period (day)`)) Df Sum Sq Mean Sq F value Pr(>F)
data$`Temperature (°C)` 1 495.6 495.6 537.476 9.7e-14 ***
data$`Period (day)` 1 1979.9 1979.9 2147.256 < 2e-16 ***
data$`Temperature (°C)`:data$`Period (day)` 1 0.1 0.1 0.138 0.715
Residuals 16 14.8 0.9
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1二元配置分散分析では、2の要因に対するp値と要因の交互作用のp値が出力されます。
有意水準を5%とする場合、p値が0.05未満であれば、対立仮説を採択し、少なくとも1つの群の平均値が他と異なると判断します。
この結果からは、温度と期間の効果に有意差が見られ、交互作用の有意差は見られないことがわかります。
対応のある二元配置分散分析
次のデータを使用します。
通常の二元配置分散分析のコードにError()関数を追加します。
summary(aov(目的変数 ~ 説明変数1 * 説明変数2 + Error(ID/(説明変数1 * 説明変数2))))
# データ読み込み
data <- read.csv(file.choose(), check.names = FALSE)
# データの整理
data$`Temperature (°C)` <- as.factor(data$`Temperature (°C)`)
data$`Period (day)` <- as.factor(data$`Period (day)`)
data$ID <- as.factor(data$ID)
# aov関数を使用して分散分析を実行
summary(aov(data$`Height (cm)` ~ data$`Temperature (°C)` * data$`Period (day)` + Error(data$ID/(data$`Temperature (°C)` * data$`Period (day)`))))Error: data$ID
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 4 4.763 1.191
Error: data$ID:data$`Temperature (°C)`
Df Sum Sq Mean Sq F value Pr(>F)
data$`Temperature (°C)` 1 495.6 495.6 994.9 6.02e-06 ***
Residuals 4 2.0 0.5
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Error: data$ID:data$`Period (day)`
Df Sum Sq Mean Sq F value Pr(>F)
data$`Period (day)` 1 1979.9 1979.9 11082 4.88e-08 ***
Residuals 4 0.7 0.2
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Error: data$ID:data$`Temperature (°C)`:data$`Period (day)`
Df Sum Sq Mean Sq F value Pr(>F)
data$`Temperature (°C)`:data$`Period (day)` 1 0.128 0.1277 0.07 0.804
Residuals 4 7.283 1.8207 二元配置分散分析では、2の要因に対するp値と要因の交互作用のp値が出力されます。
有意水準を5%とする場合、p値が0.05未満であれば、対立仮説を採択し、少なくとも1つの群の平均値が他と異なると判断します。
この結果からは、温度と期間の効果に有意差が見られ、交互作用の有意差は見られないことがわかります。
計算結果が変わるので、IDのデータ型をFactor型にしてください。
Error()関数内の説明変数1 * 説明変数2を括弧で囲み忘れに注意です。
Error(ID/(説明変数1 * 説明変数2))
Error(ID/説明変数1 * 説明変数2)
次回はTukeyの多重比較の方法について紹介します。

