
研究室に配属されたばかりの新入生や、これからRで統計分析を始めたいと思っている方へ向けて、【R講座】では、RとRStudioの基本的な使い方から統計手法の選び方、基本的なデータ分析方法までを解説しています。
特にRが初めての方でも安心して学べるように、難しいコマンドやコードは少なめで、RStudioのクリック操作を中心に進めていくので、プログラミングの経験がなくても大丈夫です。
実際のコードを交えながら進めるので、これからの研究やデータ分析に、ぜひ役立ててください!

Rは統計検定を行うことのできる強力なツールですが、統計検定はデータの種類や目的に応じて適切なものを選ぶことが重要です。
この記事では、論文でよく見かける単変量解析の手法をデータの特徴から選ぶ方法について紹介します。
データの特徴
検定の種類
統計検定には大きく分けて差を調べる検定と関連性を調べる検定があります。
- 差を調べる検定:例えば、t検定やANOVA(分散分析)など。
- 関連性を調べる検定:例えば、相関分析や回帰分析など。
対応の有無
データが対応(ペア)か非対応(独立)かを確認します。
例えば、同じ被験者の前後比較なら対応、異なる被験者群なら非対応です。
データの尺度
データの尺度には次の4種類があります。それぞれに適した検定が存在します。
- 名義尺度:カテゴリデータ(例:性別、血液型)
- 順序尺度:順序があるデータ(例:アンケートの満足度)
- 間隔尺度:等間隔の数値データ(例:温度)
- 比例尺度:絶対的なゼロ点がある数値データ(例:身長、体重)
母集団分布
検定には、データの母集団が正規分布に従うことを仮定したものと、そうでないものがあります。
データのヒストグラムを描いて視覚的に判断する方法や、正規性の検定によって判断する方法があります。
- パラメトリック検定:母集団が正規分布に従うことを前提(例:t検定、分散分析)。
- ノンパラメトリック検定:母集団の分布を仮定しない(例:マンホイットニーのU検定、クラスカル・ウォリス検定)。
群数
比較する群数が2群か3群以上かのどちらかで検定の方法を使い分けます。
母集団と標本
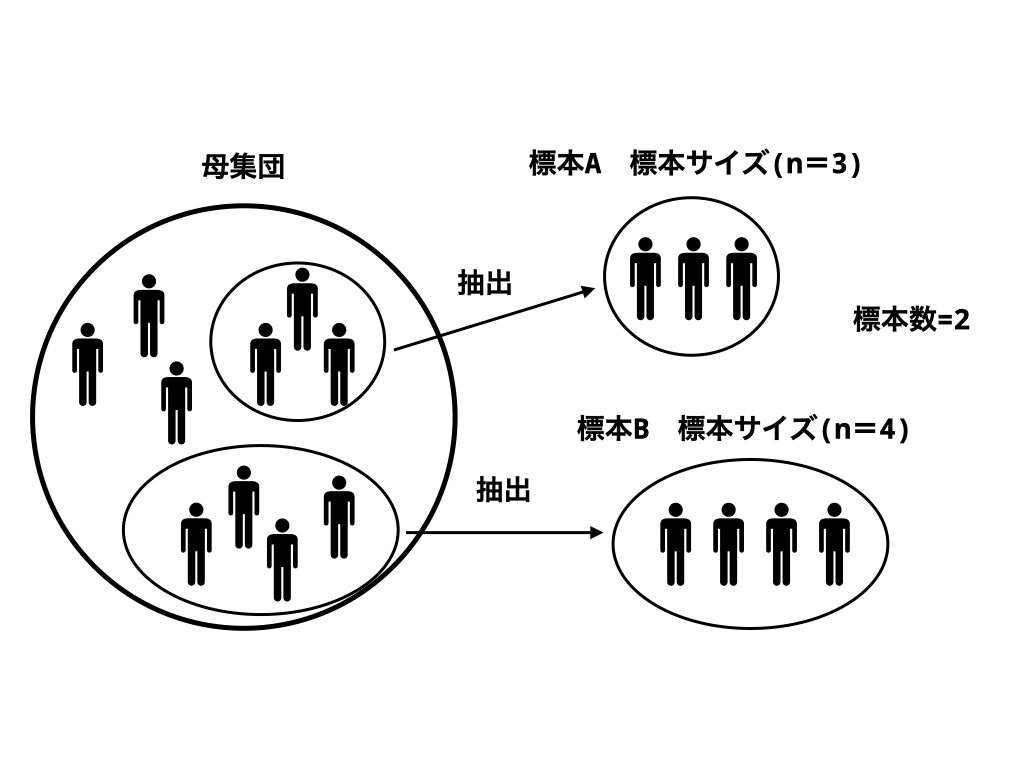
母集団
母集団とは、調査や研究の対象となる全体の集まりのことです。
標本
標本は、母集団から抽出された一部のデータのことです。標本を用いることで、母集団の特性を推測します。
標本数
標本数は、標本の抽出を行った回数(群数)のことです。
標本サイズ
標本サイズは各標本に含まれる個体数(n数)のことです。
検定手法まとめ
これまで紹介したデータの特徴から、それぞれに適した検定手法をまとめました。
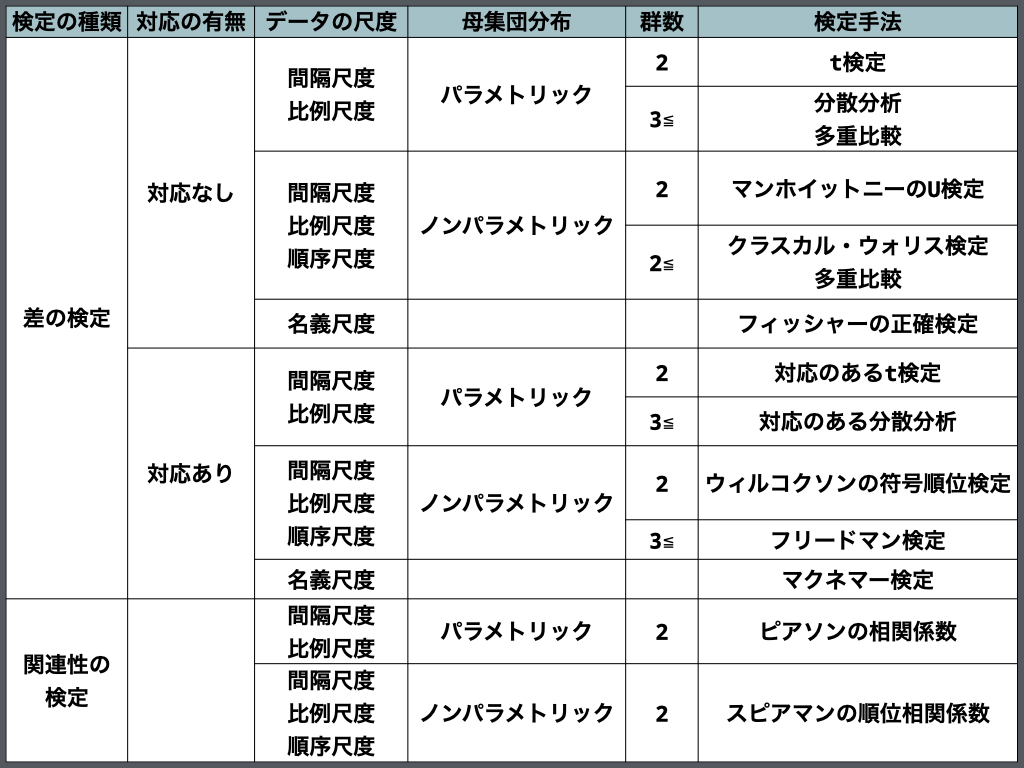
それぞれの検定については別の記事で詳しく紹介していきます。


Tukeyの多重比較

マンホイットニーのU検定

クラスカル・ウォリス検定

Steel-Dwass検定

ウィルコクソンの符号順位検定

フィッシャーの正確検定





スピアマンの相関係数

この記事は統計検定の選び方についてまとめました。
次回はt検定についてRのコードを交えながら紹介していきます。
この記事が少しでもお役に立てたら嬉しいです。

